

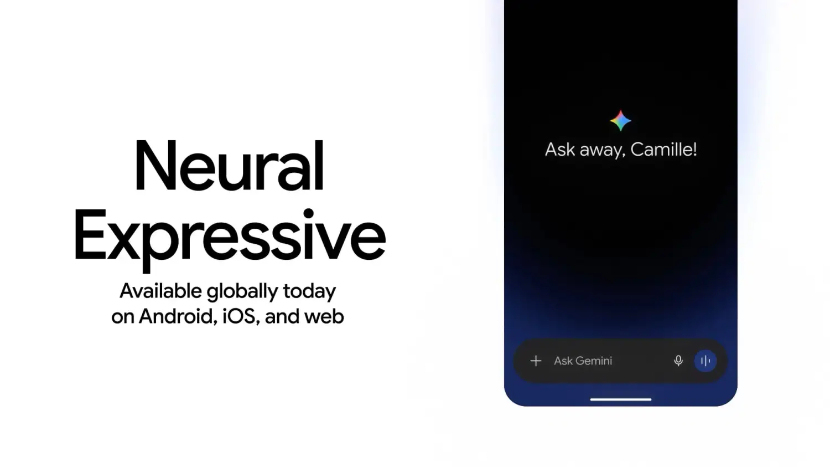
Neural Expressive to świeże podejście do wyglądu i zachowania aplikacji Gemini, które ma odejść od statycznych, tekstowych odpowiedzi na rzecz bardziej żywych i angażujących interakcji. Interfejs zyskał płynne animacje, wyraziste kolory, nową typografię i rozbudowane wykorzystanie haptyki, co ma zwiększyć wrażenie „namacalności” kontaktu z asystentem.
Pole wprowadzania poleceń przyjmuje teraz formę pigułki, w której kluczową rolę odgrywa minimalistyczny przycisk „plus”, otwierający dolny panel z karuzelą opcji przesyłania treści. Google porządkuje tu typy danych: najpierw zdjęcia, aparat i ostatnie obrazy, a dopiero po przewinięciu pojawiają się pliki, Dysk i Notatniki.
Tutaj umieszczono też dostęp do narzędzi takich jak Guided learning, Deep research, Canvas czy kreatory muzyki, wideo, obrazów oraz Personal Intelligence. Z drugiej strony znajdziemy dyktowanie oraz Gemini Live, które przestało być osobnym pełnoekranowym trybem – teraz integruje się z aplikacją i nakładką, dzięki czemu użytkownik nie musi przełączać się między różnymi widokami.
Wrócił również selektor modelu, ulokowany jako rozwijane menu w lewym górnym rogu, co ułatwia świadome wybieranie wariantu AI w zależności od zadania.
Przebudowie uległa także nawigacja, która stała się pełnoekranową szufladą zawierającą bardziej smukły zestaw ikon i pozycje takie jak New chat, Search chats, Library (dawniej My stuff) oraz Gems, do których dostęp nie jest już tak natychmiastowy jak wcześniej. Listę uzupełniają Notebooks i Recent, a na dole znalazły się zdjęcie profilowe oraz zębatka prowadząca do ustawień konta.
Kluczowa zmiana dotyczy samej formy odpowiedzi, które mają przestać przypominać „ściany tekstu”. Gemini ma prezentować najważniejsze informacje u góry, wyróżnione pogrubieniem, a tam, gdzie to ma sens, wzbogacać wynik o obrazy w treści, narracyjne wideo, oś czasu czy interaktywne wizualizacje, co wpisuje się w trend bardziej multimodalnej komunikacji.
Nowy design Neural Expressive wdrażany jest jednocześnie na Androidzie, iOS oraz w wersji webowej aplikacji Gemini, co podkreśla znaczenie spójności doświadczenia między platformami.
Gemini 3.5 Flash to nowy model, który łączy tzw. frontier intelligence z możliwością wykonywania zadań agentowych, czyli realnych akcji w imieniu użytkownika. Google podkreśla, że w testach przewyższa on Gemini 3.1 Pro w obszarach programowania, zdolności agentowych oraz multimodalnych benchmarków.
Przy tym wszystkim 3.5 Flash pozostaje wierny DNA serii Flash, oferując nawet czterokrotnie wyższą przepustowość generowanych tokenów na sekundę w porównaniu z innymi modelami frontier. Dodatkową przewagą jest koszt – nowy model ma być około jedna trzecia do połowy tańszy w użyciu, co ma znaczenie zarówno dla użytkowników końcowych, jak i deweloperów sięgających po API.
W praktyce Gemini 3.5 Flash trafia od razu do kilku produktów, w tym aplikacji Gemini, wyszukiwarki, środowiska Google Antigravity 2.0 oraz interfejsu Gemini API. To oznacza, że użytkownicy i twórcy aplikacji mogą od razu korzystać z nowego modelu zarówno w kontekście czatbotów, jak i automatyzacji procesów.
Pokazano też Gemini Omni - nowy model, który ma łączyć zdolności wnioskowania z kreatywnym generowaniem treści, szczególnie multimedialnych. Google określa go jako rozwiązanie pozwalające „tworzyć cokolwiek z dowolnego wejścia”, z naciskiem na generowanie wideo.
Wejściem mogą być obrazy, dźwięk, wideo lub tekst, a powstające materiały mają być zakotwiczone w wiedzy o świecie, co ma ograniczyć halucynacje i zapewnić większą spójność z rzeczywistością. Kluczową cechą jest możliwość łatwej edycji za pomocą tekstu, co pozwala użytkownikowi precyzyjnie korygować lub rozwijać wygenerowane treści.
W aplikacji Gemini użytkownik może wgrać dowolne zdjęcie czy wideo i skorzystać z wbudowanych szablonów edycji, co zbliża doświadczenie do narzędzi montażowych, ale sterowanych językiem naturalnym. Jedną z bardziej efektownych funkcji jest tworzenie niestandardowych awatarów AI, które wyglądają i brzmią jak użytkownik, a następnie osadzanie ich w scenach akcji.
Gemini Omni w wariancie Flash zaczyna być udostępniany użytkownikom planów Google AI Plus, Pro i Ultra na całym świecie

Gemini Spark firma z Mountain View opisuje jako „osobistego agenta”, który ma wykonywać konkretne działania, by pomóc użytkownikowi poruszać się po cyfrowym życiu. Działa na dedykowanych maszynach wirtualnych Google Cloud, funkcjonując 24/7 i będąc dostępny z dowolnego urządzenia poprzez aplikację Gemini.
Dostęp do Sparka ma się rozszerzyć także na bardziej klasyczne kanały, takie jak e‑mail i SMS, a w dalszej kolejności na przeglądarkę Chrome. Na urządzeniach mobilnych pojawi się interfejs Android Halo, który ma prezentować na żywo aktualizacje i postęp wykonywanych zadań, dzięki czemu użytkownik widzi, nad czym agent pracuje w danej chwili.
Spark ma wymagać potwierdzenia przy czynnościach o wysokim ryzyku, jak wysyłanie e‑maili czy wydawanie pieniędzy, co stanowi zabezpieczenie przed niechcianymi działaniami. Google przedstawia Sparka jako przełom w roli Gemini – z asystenta odpowiadającego na pytania ma stać się partnerem wykonującym realną pracę na zlecenie użytkownika.
Technicznie Spark korzysta z Gemini 3.5 Flash oraz pełnego „harnessu” Google Antigravity, co ma pozwolić na realizację tzw. zadań o długim horyzoncie, obejmujących m.in. pisanie kodu i złożone przepływy pracy. Integracja zaczyna się od usług Google, takich jak Gmail, Dokumenty i pozostałe aplikacje Workspace, a latem ma rozszerzyć się na narzędzia zewnętrzne za pośrednictwem MCP.
Google podaje konkretne przykłady użycia: Spark może automatycznie analizować miesięczne wyciągi z kart kredytowych w poszukiwaniu nowych lub ukrytych subskrypcji. Innym scenariuszem jest nauczenie agenta śledzenia e‑maili ze szkoły dzieci, wyciągania kluczowych terminów i wysyłania skonsolidowanego dziennego podsumowania do obojga rodziców.
Spark potrafi też tworzyć bardziej złożone akcje, np. na podstawie surowych notatek z różnych e‑maili i czatów przygotować dopracowany dokument Google oraz szkic e‑maila inicjującego projekt. Początkowo będzie dostępny w kolejnym tygodniu dla użytkowników planu Google AI Ultra w USA, z poziomu nawigacji aplikacji, gdzie pojawią się zakładki „Chat” i „Spark”.
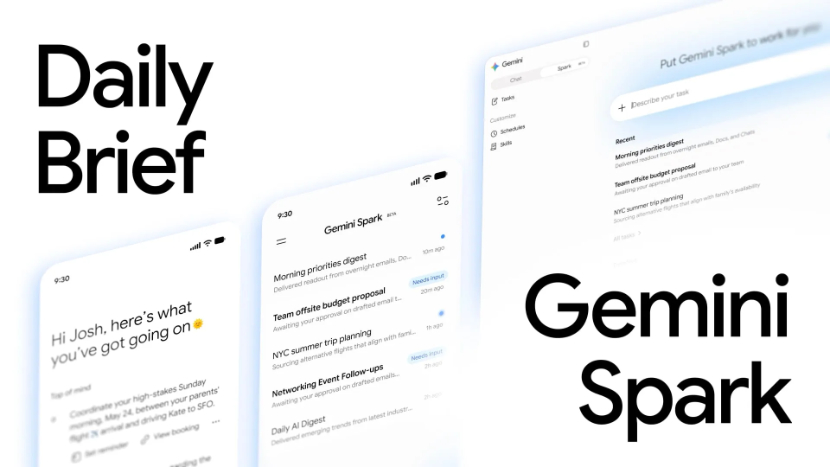
Daily Brief to agent zaprojektowany jako spersonalizowane, poranne podsumowanie dnia, wywodzące się z projektu Google Labs testowanego od zeszłego roku. Zamiast tylko streszczać informacje, ma priorytetyzować, porządkować i proponować kolejne kroki, dzięki czemu użytkownik dostaje nie tylko obraz sytuacji, ale również sugestie działania.
Funkcja pojawia się w panelu bocznym aplikacji, a każdego ranka prezentuje aktualizację tego, co przed użytkownikiem. Sekcja „Top of mind” wyróżnia zadania wymagające natychmiastowej uwagi, a pod każdym elementem znajdują się skróty, które pozwalają szybko utworzyć przypomnienie, przejrzeć wiadomości czy przygotować odpowiedzi.
Niżej umieszczono sekcję „Looking ahead”, która wskazuje rzeczy czekające w dalszej perspektywie, ułatwiając planowanie. Kluczową rolę odgrywa tu praca wykonywana przez Gemini w nocy – system analizuje Gmaila, Kalendarz i Zadania, by przygotować pełniejszy obraz nadchodzącego dnia.
Daily Brief trafia do użytkowników planów Google AI Plus, Pro i Ultra, począwszy od dzisiejszego dnia, choć początkowo tylko w Stanach Zjednoczonych.
Pytanie, czy tym razem w końcu będzie działać to zgodnie z obietnicami, bowiem poprzednie wcielenie na Pixelach czy podobny pomysł od Samsunga (Now Brief) delikatnie mówiąc nie dowiozły obietnic tworców.
Na koniec Google wprowadza nowe poziomy cenowe dla Google AI Ultra, które dają dostęp do wszystkich opisanych wyżej funkcji. Podstawowy plan ma startować od 99,99 dolarów miesięcznie, a droższa opcja za 200 dolarów oferuje najwyższe limity korzystania z usług.
Źródło: 9To5Google